Meltdown
Table of Contents
Meltdown
1:retry:2:mov al, byte [rcx] // 读取地址 rcx 处一字节的数据到寄存器 rax3:shl rax, 0xC // 将刚读取到数据乘 40964:jz retry5:mov rbx, qword [rbx + rax] // 读取 rbx+rax 处的数据(位于我们开辟的用户区数据)
-
一页数据为
4096字节(1 << 0xC = 4096) -
rbx中地址开始256*4096长度的内存位于用户区(256 页的数据)。 rcx中为内核空间的地址
第 1 行代码执行的是非法操作,读取内核空间
rcx 地址的一个字节(设这个字节为 x )到
al ,它会触发异常,但是由于分支预测的存在,第 2、3、4
行可能被先执行,第 2 行将获取的一个字节的数据(该数据范围
0~255 )乘以~4096~ 存在 rax ,访问
rbx+rax 数据,这是用户区数据,它被缓存。
异常处理时,会撤销分支预测时执行的那些代码,清空相关寄存器,因此寄存器里面不会直接存有我们想要的数据(那一个字节)。
漏洞就是,上面最后一步对于用户区数据的缓存没有被撤销。
因此,如果这段代码执行之前我们实现清理缓存确保用户区我们开辟的那
256 页数据没有被缓存,执行这段代码后,这
256 页中有一页是被缓存的,也即
rbx + x*4096 。我们依此访问
rbx + n*4096 (
n: 0~255 )记录这些位置的访问时间,时间最短的那次的
n 就是 x 。
还有就是第 3 行是干嘛要说明一下,执行第 1 行时触发异常,异常处理时会清空相关寄存器,如果异常处理在执行完第 2 行时就执行,那么~rax~ 将为 0,不是我们需要的值,所以对于这种情况我们跳过。
下图截自 Meltdown1。
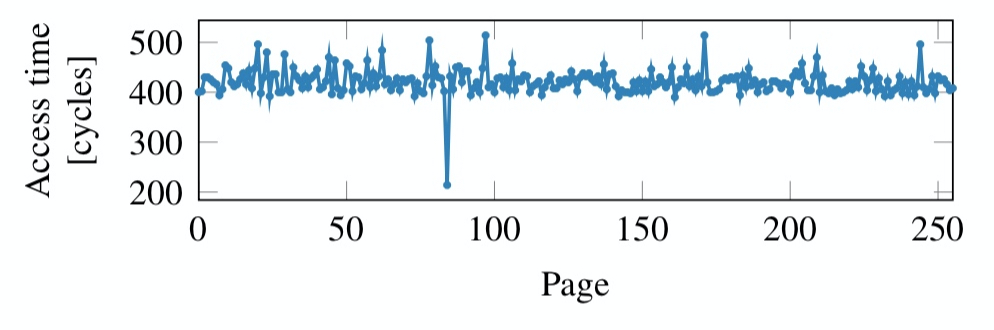
Figure 1: 展示遍历访问 256 页数据时每页的访问时间,通过 meltdown 攻击缓存的页的数据访问时间明显较短